Amazon Rezensionen mit BERTopic analysieren - Python Guide

Trutz Fries
In diesem Artikel zeigen wir Ihnen, wie Sie mit BERTopic und Python automatisch relevante Themen aus Amazon Rezensionen extrahieren können. Mit nur wenigen Zeilen Code gewinnen Sie wertvolle Insights aus Kundenfeedback - ideal für die Produktoptimierung und Marktanalyse. Das komplette Jupyter Notebook finden Sie am Ende des Artikels.
Was ist BERT?
BERT steht für “Bidirectional Encoder Representations from Transformers” und ist ein von Google vortrainiertes Modell, welches im Rahmen des Natural Language Processing (NLP) angewendet wird. Es wurde mit Hilfe eines mehrschichtigen, neuronalen Netzes auf einem sehr großen Text-Korpus vor-trainiert. Dieses Training hat trotz des Einsatzes einer Vielzahl von Googles Servern mehrere Tage gedauert.
Vereinfacht gesagt wurde ein Modell entwickelt, welches die Beziehungen von Worten untereinander, sowie deren Bedeutung besser versteht als andere vergleichbare NLP Modelle. Mit Hilfe von BERT lassen sich unterschiedliche NLP Aufgaben lösen, wie z.B. das Klassifizieren von Texten, die Beantwortung einfacher Fragen oder das sog. “Named Entity Recognition” (NER), bei dem man versucht, aus einem Text die Subjekte und Objekte zu extrahieren und diese zu klassifizieren, z.B. Personen, Firmen, Datumsangaben uvm.
Was ist BERTopic?
BERTopic ist ein von Maarten Grootendorst entwickeltes Python Modul, welches auf die Extraktion von Themen aus Texten spezialisiert ist. Es nutzt dabei ein Verfahren basierend auf BERT und einer abgewandelten TF-IDF-Analyse. Wer mehr über BERTopic erfahren möchte, dem sei dieser oder dieser Artikel empfohlen. Um das folgende Beispiel nachzuvollziehen, muss man das Modul nicht im Detail verstehen.
Amazon Rezensionen mit Python analysieren
Für Marken stellen Rezensionen ein wertvolles Feedback dar, dass diese zudem noch kostenlos erhalten. Einziges Problem ist die Komplexität, die sich aus der Anzahl der Summe sowie der Anzahl der Rezensionen je Produkt ergibt. Zusätzlich müssen Verkäufer auch manipulierte Bewertungen von chinesischen Händlern im Blick behalten. Um diese Herausforderung zu meistern, empfiehlt es sich, Rezensionen kontinuierlich zu überwachen und systematisch auszuwerten.
Hier wäre daher ein Machine-Learning-Ansatz praktisch, der aus allen Rezensionen die relevanten Themen extrahiert und gruppiert.
Anhand eines Beispiels soll dies illustriert werden. Nehmen wir ein beliebtes Produkt auf Amazon mit vielen Rezensionen, den bite away.
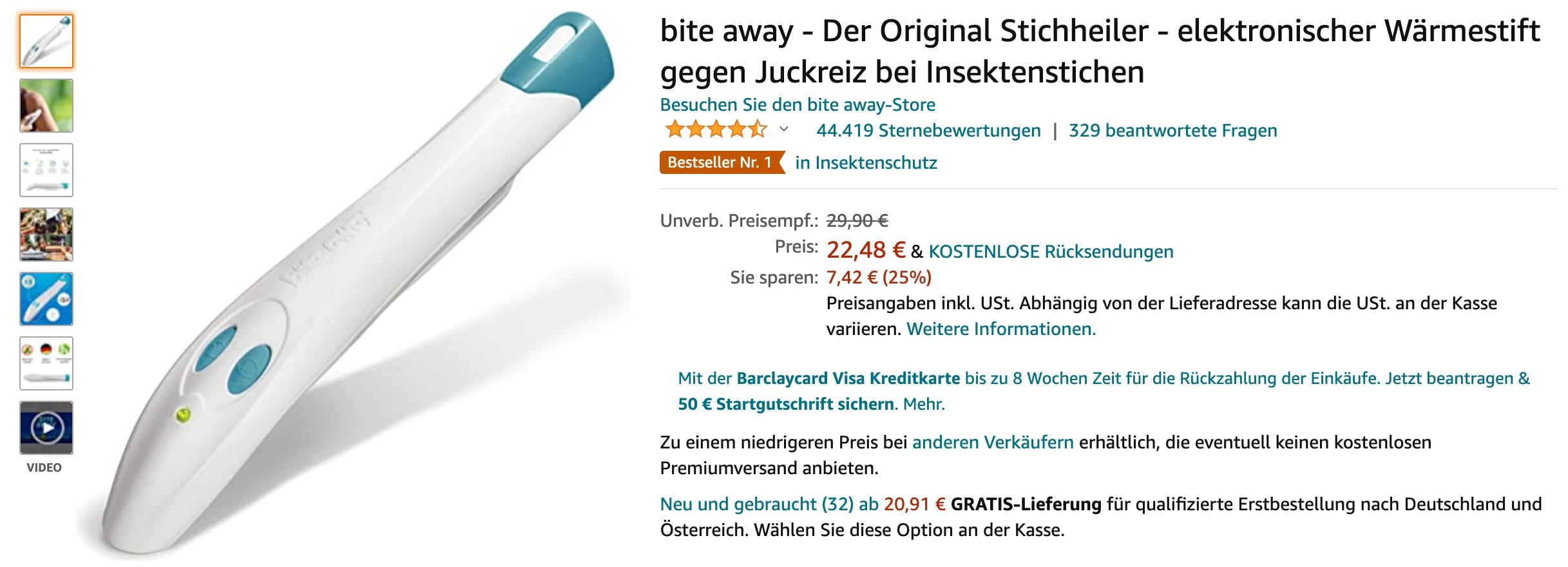
Wir nutzen ein einfaches Jupyter Notebook, um die Daten zu analysieren.
Installieren wir zuerst alle nötigen Bibliotheken:
# Install
!pip install bertopic
!pip install nltk
# Import
import pandas as pd
import numpy as np
from bertopic import BERTopic
Um später aus den Rezensionen die Stoppwörter zu entfernen, nutzen wir hierfür das nltk Modul und laden die Stoppwörter für die deutsche Sprache:
# Stopwords
import nltk
nltk.download('punkt')
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stopwords=set(stopwords.words('german'))
Für das Entfernen von Stoppwörtern benötigen wir noch eine Funktion, die aus einem Array von Sätzen / Rezensionen die Stoppwörter entfernt:
# Remove stopwords from an array of strings
def remove_stopwords(data):
output_array=[]
for sentence in data:
temp_list=[]
for word in str(sentence).split():
if word.lower() not in stopwords:
temp_list.append(word)
output_array.append(' '.join(temp_list))
return output_array
Als nächstes laden wir die Amazon Rezensionen mit Hilfe der Pandas-Bibliothek in einen DataFrame. Die Rezensionen erhalten Sie z.B. über einen detaillierten Bericht aus unserem Tool AMALYTIX. Für weitere Datenverarbeitungstechniken mit Pandas schauen Sie sich auch unseren Artikel über Amazon Bulk Operationen mit Python und Pandas an:
df = pd.read_csv("./reviews-B003CMKQTS-de.csv", engine='python')
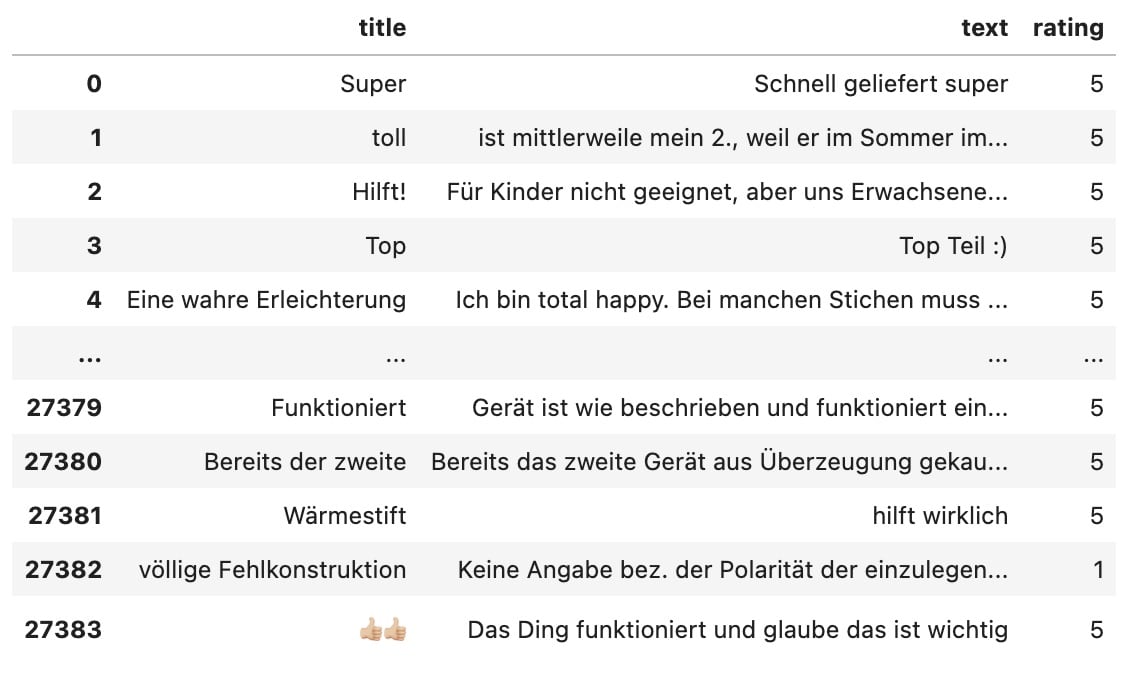
Jetzt entfernen wir aus dem Datensatz die positiven Rezensionen (4-5 Sterne), um zu verstehen, was die Kunden kritisieren. Anschließend wandeln wir den Dataframe in eine Liste um und entfernen die Stoppwörter mit Hilfe der oben definierten remove_stopwords Funktion:
# Only get critical reviews (1-3 stars)
dfNegative = df[df.rating < 4]
# Convert df column "text" to list
reviewsNegativeText = dfNegative.text.to_list()
# Remove stopwords
reviewsNegativeText = remove_stopwords(reviewsNegativeText)
Jetzt erstellen wir unser Modell basierend auf BERTopic:
modelNegative = BERTopic(language="german", nr_topics="auto")
Als nächstes müssen wir dieses Modell noch “finetunen”:
topics, probabilities = modelNegative.fit_transform(reviewsNegativeText)
Standardmäßig enthält das Modell nur einzelne Wörter. Mit Hilfe eines einfachen Modell-Updates lassen wir auch Bi-Gramme - also Kombinationen von 2 Wörtern - zu:
modelNegative.update_topics(reviewsTextFiltered, topics, n_gram_range=(1, 2))
Das wars auch schon. Jetzt können wir uns die Ergebnisse anschauen. Schauen wir uns als Erstes die Anzahl der Themenfelder an:
modelNegative.get_topic_freq().head(11)
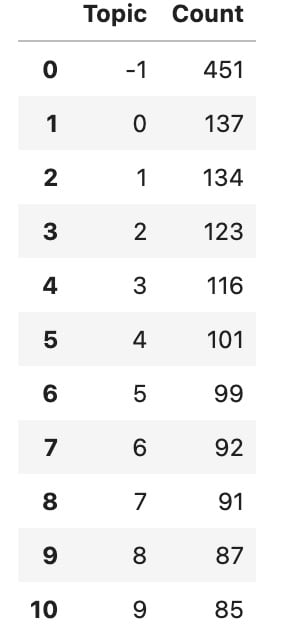
Hier sieht man die ersten zehn Themenfelder (“Topics”). Das Topic mit der -1 ist das Topic mit Inhalten, die nicht zugeordnet werden konnten, dieses können wir daher ignorieren.
Schauen wir uns mal das erste Themenfeld / Topic an:
modelNegative.get_topic(1)
[('defekt', 0.011148147661148565),
('monat', 0.008799115337334707),
('monaten', 0.007398879507378811),
('monaten mehr', 0.007363461462032497),
('abgelaufen ist', 0.007026721331499257),
('schon defekt', 0.006190625875256987),
('verspätung', 0.0061362178850270805),
('gerät bereits', 0.005747283493183007),
('rücksendefrist', 0.005500258254624393),
('gerät 3x', 0.005473215223609577)]
Hier erkennt man, dass sich viele Kunden über die mangelhafte Haltbarkeit beschweren. Scheinbar geht das Produkt häufiger mal kaputt.
Schauen wir mal in Thema 3 rein:
modelNegative.get_topic(3)
[('enttäuscht', 0.007670611779864671),
('schmerzhaft', 0.006489256905951043),
('heiß', 0.006296142117342345),
('schmerz', 0.006095052433498948),
('heiß kinder', 0.006035989865595163),
('hitze', 0.005749678921426524),
('weh nützt', 0.005692691419037523),
('tut weh', 0.005277188297220635),
('empfindlich', 0.005030634228804426),
('eigentlich empfindlich', 0.0050215790931766755)]
Das Produkt scheint einigen Anwendern auch etwas weh zu tun! Das ist bei diesem Produkt auch kein Wunder, da es Mückenstiche mit Hilfe von Hitze bekämpft.
Um schnell die relevanten Keywords je Topic anzuzeigen, eignet sich diese kurze Schleife:
for x in range(0, 10):
first_tuple_elements = []
for tuple in modelPositive.get_topic(x):
first_tuple_elements.append(tuple[0])
print(first_tuple_elements)
print("\n")
Ergebnis:
['sterne', 'verarbeitung', 'höllisch weh', 'erwachsene', 'stunde', 'kurze zeit', 'stift eingesetzt', 'eingesetzt stunde', 'sterne verdient', 'zwei punkte']
['defekt', 'monat', 'monaten', 'monaten mehr', 'abgelaufen ist', 'schon defekt', 'verspätung', 'gerät bereits', 'rücksendefrist', 'gerät 3x']
['preis', 'billig', 'wirkung', 'käufer', 'kaufen', 'schlechter', 'schlecht konstruiert', 'neue batterien', 'batteriedeckel', 'bewertungen']
Wir können die Themenfelder auch einfach visualisieren:
modelNegative.visualize_barchart()
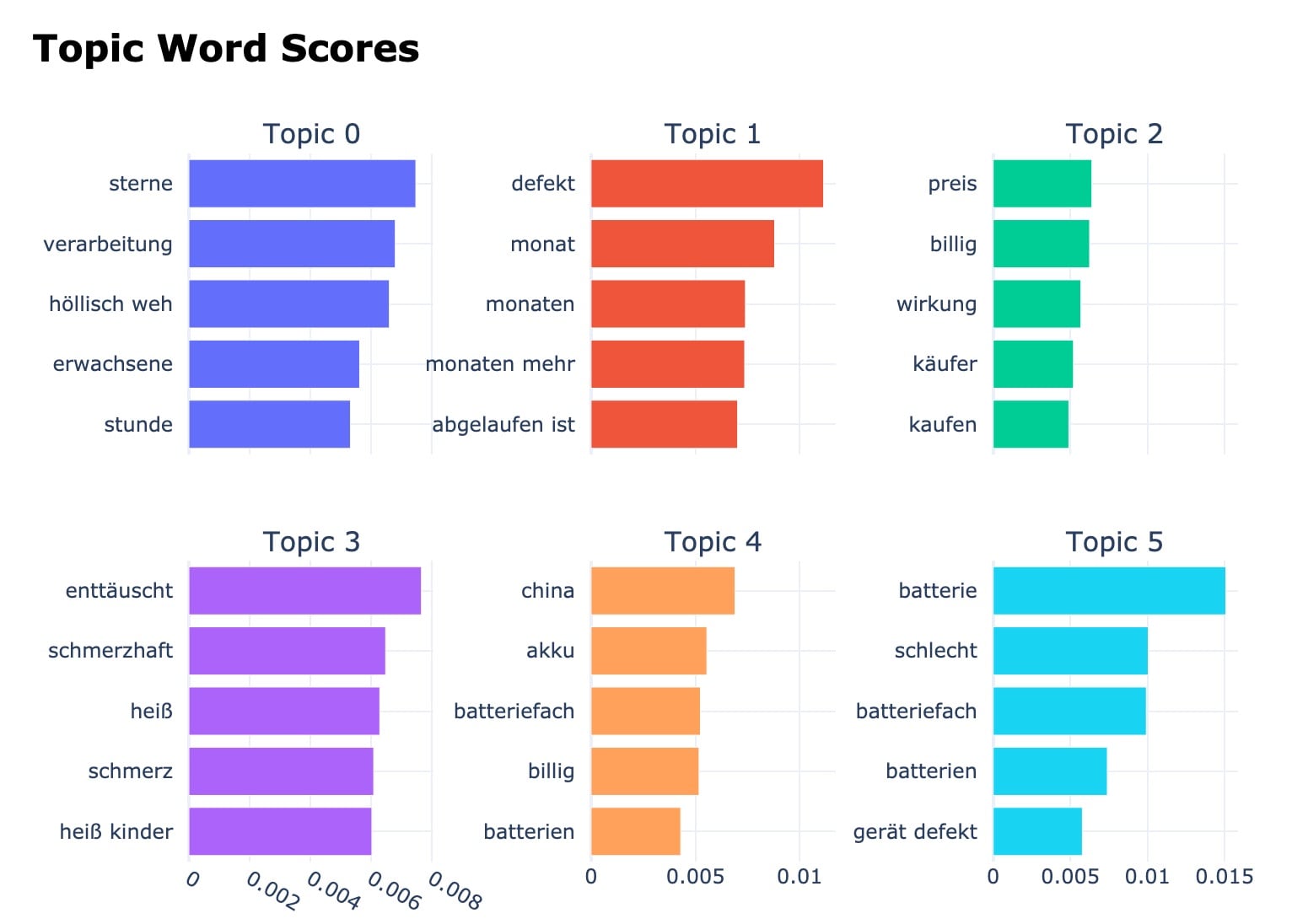
Auch ein graphisches Clustering der Themen ist möglich:
modelNegative.visualize_hierarchy(top_n_topics=20)
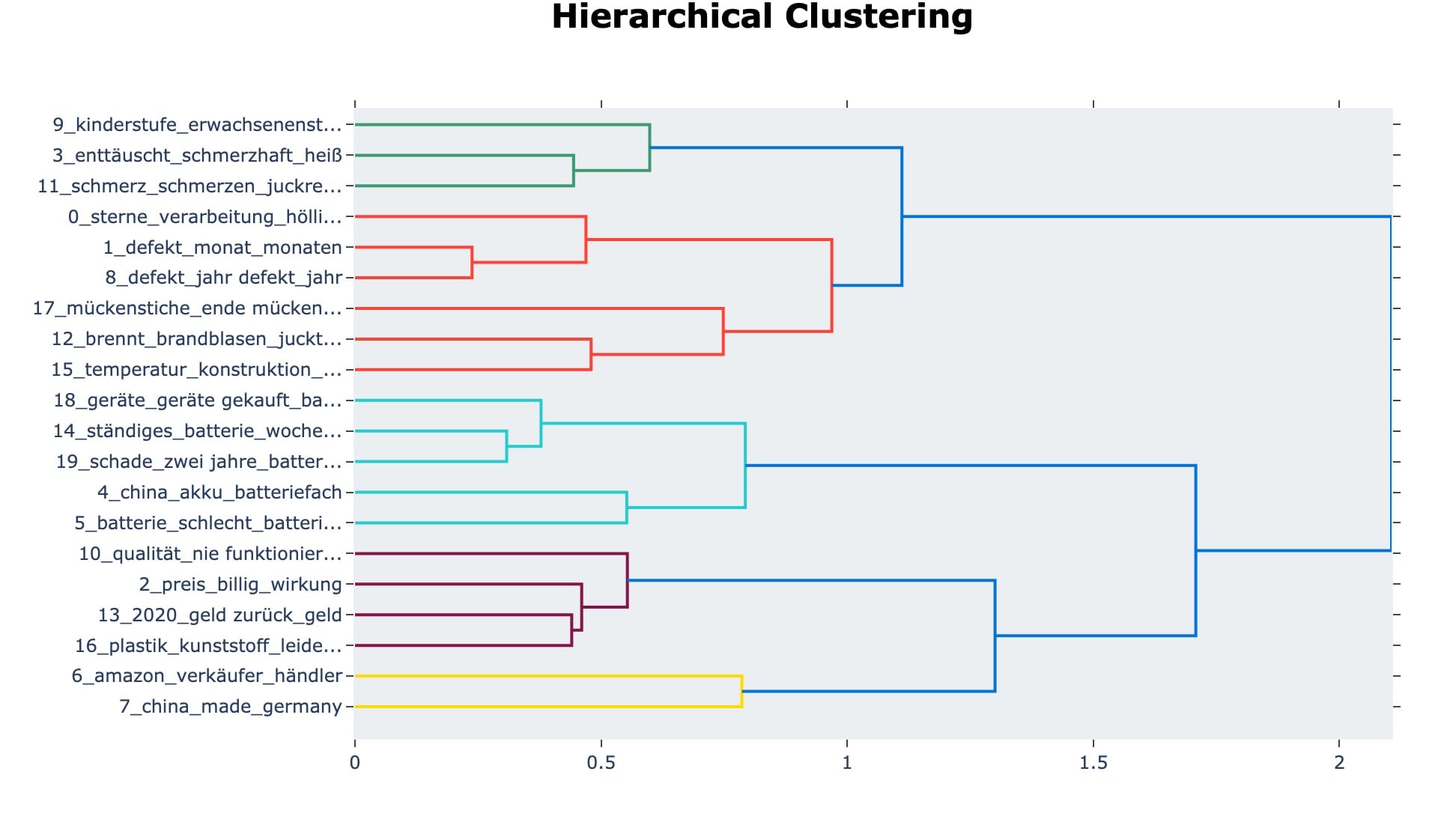
Wenn wir das mal vergleichen mit den Schlagworten, die Amazon extrahiert, dann können sich die Ergebnisse sehen lassen:
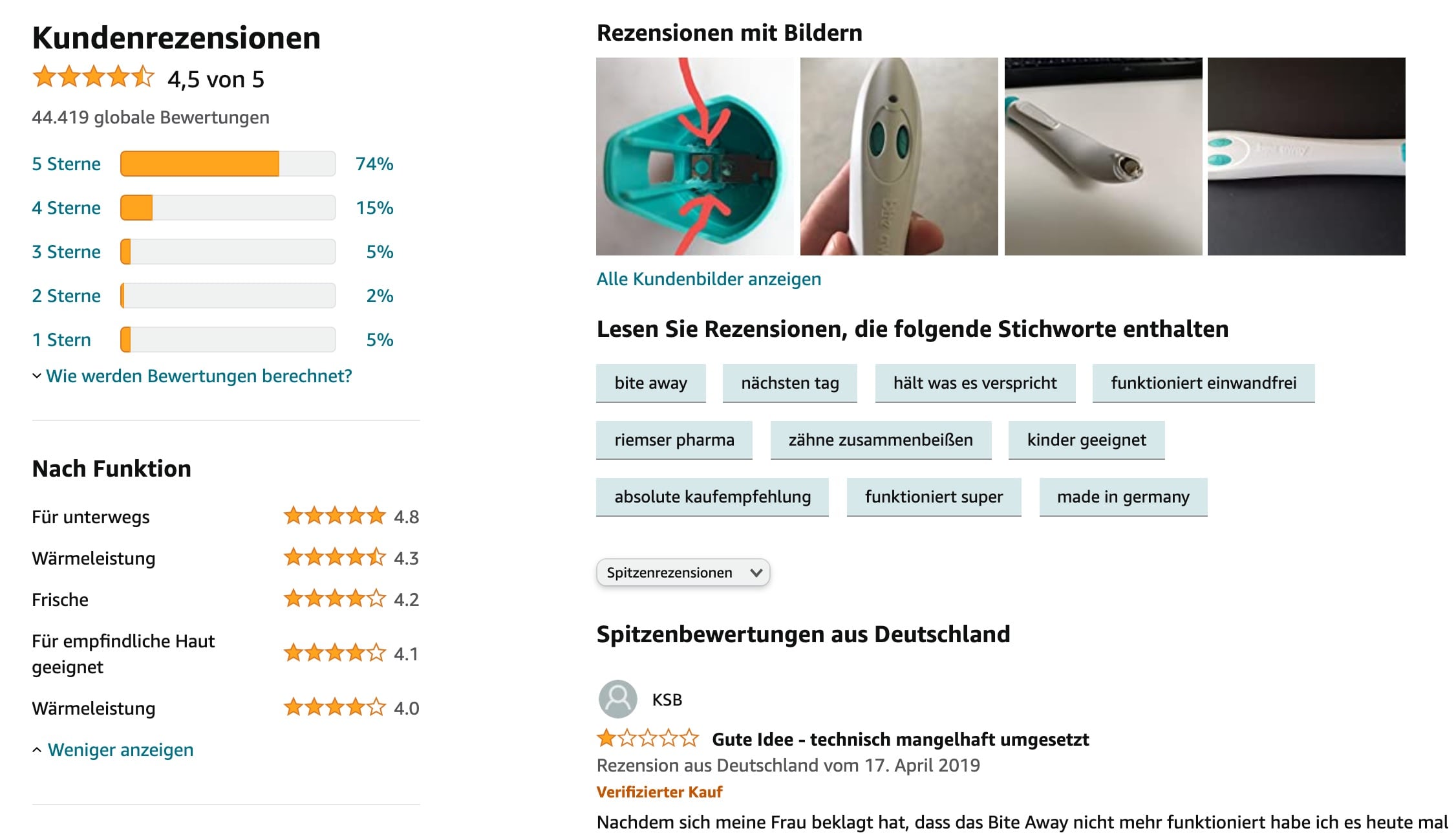
Fazit: BERTopic für Amazon Rezensionen-Analyse
Mit nur 30 Zeilen Python Code konnten wir mit BERTopic relevante Themen aus Amazon Rezensionen extrahieren. Die automatische Analyse liefert wertvolle Insights für die Produktoptimierung und das Verständnis von Kundenbedürfnissen. Trotz der Rechenzeit von einigen Minuten pro Produkt ist die BERTopic-Analyse deutlich effizienter als manuelle Auswertungen.
Das komplette Jupyter Notebook mit allen Code-Beispielen können Sie hier auf GitHub herunterladen.
Newsletter abonnieren
Erhalten Sie die neuesten Amazon-Tipps und Updates direkt in Ihr Postfach.
Wir respektieren Ihre Privatsphäre. Jederzeit abbestellbar.