Analyze Amazon Reviews with BERTopic and Python: Complete Guide
Trutz Fries
Amazon reviews contain valuable customer insights that can drive product improvements. In this tutorial, we’ll show you how to analyze Amazon reviews using BERTopic and Python to extract relevant topics and understand customer feedback patterns. The complete Jupyter Notebook is available at the end of the article.
For more ways to leverage Amazon data, explore our guides on Amazon review monitoring and Python tools for Amazon analysis.
What is BERT for Amazon Review Analysis?
BERT stands for “Bidirectional Encoder Representations from Transformers,” a model pre-trained by Google and applied in Natural Language Processing (NLP). It was pre-trained using a multilayered neural network on a very large text corpus. Despite the use of many Google servers, this training took several days.
Simply put, a model was developed that understands the relationships between words and their meaning better than other comparable NLP models. BERT can solve various NLP tasks such as text classification, answering simple questions, or “Named Entity Recognition” (NER), which aims to extract and classify subjects and objects from a text, e.g., people, companies, dates, and much more.
Understanding BERTopic for Amazon Reviews
BERTopic is a Python module developed by Maarten Grootendorst, specialized in extracting topics from texts. It uses a method based on BERT and a modified TF-IDF analysis. If you want to learn more about BERTopic, check out this or this article. You don’t need to understand the module in detail to follow the example below.
How to Analyze Amazon Reviews with BERTopic
For brands, reviews are valuable feedback they receive for free. The only problem is the complexity arising from the total number and the number of reviews per product.
This is where a machine learning approach can be practical, extracting and grouping relevant topics from all reviews.
An example will illustrate this. Let’s take a popular product on Amazon with many reviews, the bite away.
We’ll use a simple Jupyter Notebook to analyze the data.
First, let’s install all necessary libraries:
# Install
!pip install bertopic
!pip install nltk
# Import
import pandas as pd
import numpy as np
from bertopic import BERTopic
To remove stop words from the reviews later, we’ll use the nltk module and download the stop words for the German language:
# Stopwords
import nltk
nltk.download('punkt')
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stopwords=set(stopwords.words('german'))
We’ll need a function to remove stop words from an array of sentences/reviews:
# Remove stopwords from an array of strings
def remove_stopwords(data):
output_array=[]
for sentence in data:
temp_list=[]
for word in str(sentence).split():
if word.lower() not in stopwords:
temp_list.append(word)
output_array.append(' '.join(temp_list))
return output_array
Next, we’ll load the reviews into a DataFrame using the Pandas library. You can obtain the reviews, for example, via a report from our AMALYTIX tool:
df = pd.read_csv("./reviews-B003CMKQTS-de.csv", engine='python')
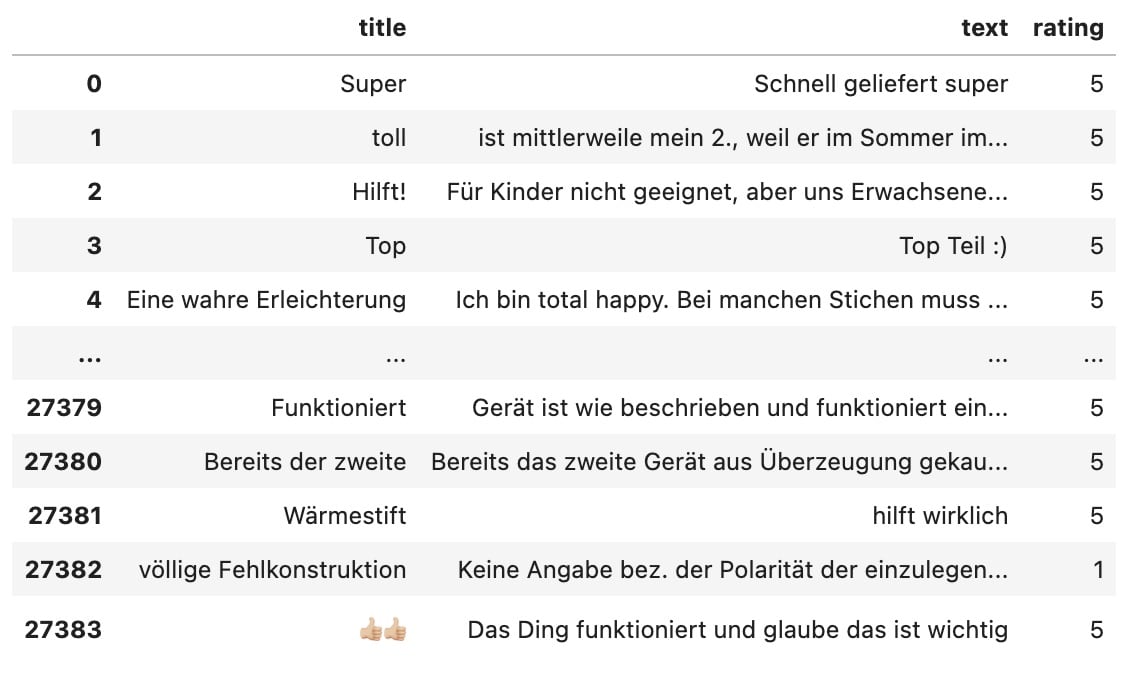
Now, we’ll remove the positive reviews (4-5 stars) from the dataset to understand what customers criticize. We’ll then convert the DataFrame into a list and remove the stop words using the remove_stopwords function defined above:
# Only get critical reviews (1-3 stars)
dfNegative = df[df.rating < 4]
# Convert df column "text" to list
reviewsNegativeText = dfNegative.text.to_list()
# Remove stopwords
reviewsNegativeText = remove_stopwords(reviewsNegativeText)
Now, let’s create our model based on BERTopic:
modelNegative = BERTopic(language="german", nr_topics="auto")
Next, we need to “fine-tune” this model:
topics, probabilities = modelNegative.fit_transform(reviewsNegativeText)
By default, the model only contains single words. Using a simple model update, we’ll also include bi-grams (combinations of 2 words):
modelNegative.update_topics(reviewsTextFiltered, topics, n_gram_range=(1, 2))
That’s it. Now we can take a look at the results. Let’s first look at the number of topics:
modelNegative.get_topic_freq().head(11)
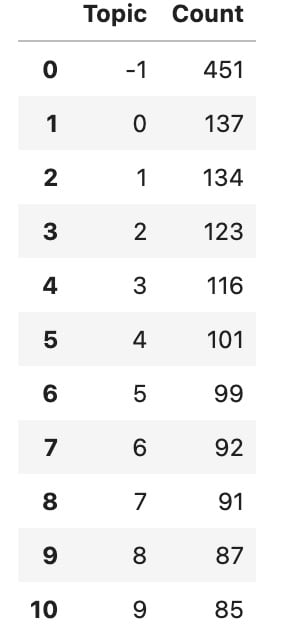
Here you can see the first ten topics. The topic with -1 is the topic with unassigned content, so we can ignore it.
Let’s look at the first topic:
modelNegative.get_topic(1)
[('broken', 0.011148147661148565),
('month', 0.008799115337334707),
('months', 0.007398879507378811),
('months more', 0.007363461462032497),
('is broken', 0.007026721331499257),
('already broken', 0.006190625875256987),
('late', 0.0061362178850270805),
('device alredy', 0.005747283493183007),
('return period', 0.005500258254624393),
('device 3x', 0.005473215223609577)]
Here you can see that many customers complain about poor durability. It seems the product breaks down quite often.
Let’s check out topic 3:
modelNegative.get_topic(3)
[('disappointed', 0.007670611779864671),
('painful', 0.006489256905951043),
('hot', 0.006296142117342345),
('pain', 0.006095052433498948),
('hot children', 0.006035989865595163),
('heat', 0.005749678921426524),
('pain use', 0.005692691419037523),
('hurts', 0.005277188297220635),
('sensitive', 0.005030634228804426),
('actually sensitive', 0.0050215790931766755)]
It seems the product causes pain for some users, which isn’t surprising since it fights mosquito bites using heat.
To quickly display relevant keywords for each topic, this simple loop is useful:
for x in range(0, 10):
first_tuple_elements = []
for tuple in modelPositive.get_topic(x):
first_tuple_elements.append(tuple[0])
print(first_tuple_elements)
print("\n")
Result:
['stars', 'processing', 'hell of a pain', 'adult', 'hour', 'short time', 'pen inserted', 'inserted hour', 'stars earned', 'two points']
['defective', 'month', 'months', 'months more', 'expired', 'already defective', 'delay', 'device already', 'return period', 'device 3x']
['price', 'cheap', 'effect', 'buyer', 'buy', 'worse', 'poorly constructed', 'new batteries', 'battery cover', 'reviews']
If we compare this with the keywords Amazon extracts, the results are impressive:
- bite away
- next day
- keeps the promise
- works perfect
- riemser pharma
- clench your teeth
- for kids
- works perfectly
- absolute purchase recommendation
- made in germany
Key Takeaways for Amazon Review Analysis
With around 30 lines of code, we were able to extract relevant information from Amazon reviews. The challenge in analyzing multiple products is the duration. Tuning the model via the fit_transform
method takes a few minutes each time. Nevertheless, the effort could be worthwhile, especially since manual analysis certainly won’t be faster.
You can download the notebook here.
Subscribe to Newsletter
Get the latest Amazon tips and updates delivered to your inbox.
We respect your privacy. Unsubscribe anytime.
